Automating My Development Workflow

In my last post, I explored what it would take to trust AI-generated code enough to ship it without review. The conclusion was that layering systems like better specifications, tamper-proof tests, and enforceable conventions might provide enough trust that we humans can focus our attention on the parts in which the AI lacks confidence.

After publishing that post, I kept thinking about how to integrate some of these systems into my own development process. But like most of us, I don't actually own that process. For one, it lives inside the tools I use: the coding agent, the IDE, the CI pipeline. But more importantly, I can't meaningfully experiment with it because it is not actually a defined process. I have my way of working, but that differs slightly from task to task.
So I decided to codify my own process. I took my existing workflow with Claude Code, from specification to plan to implementation, and wrapped it in a lightweight automation harness. The goal was to turn an ad-hoc workflow into an artifact that I can experiment with to test my own ideas about productivity and trust.
Development Process as an Artifact
The first version was a deliberately simple CLI that took a Markdown task description and walked it through a fixed pipeline: create a branch, pass the task to a coding agent, run validations like tests and lints, and then push the code. Every transition between steps required my approval. The agent did the work, the custom harness handled the plumbing.
As soon as my workflow was an explicit artifact I could modify and change, something interesting happened: Instead of trying to layer the systems from my previous blog post onto my process, I started iterating on the process itself. Every manual action triggered the question if the harness or agent could do it for me. Every small idiosyncrasy or inefficiency stood out.
Within just a week, the workflow grew from five steps with a human gate at each one to a pipeline with branching logic, automated review loops, and a single human approval at the very end.
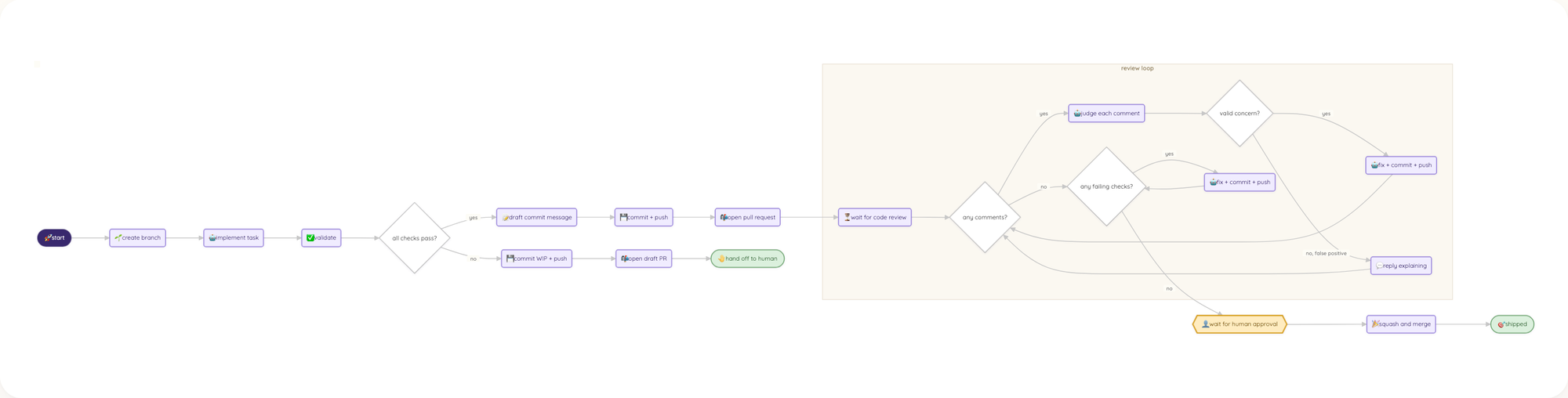
Iterating on the process itself provided more value to me than adding additional controls. Going through the workflow a few times made me understand where I already trusted the AI, where I simply passed output from other tools back into Claude, and where the actual gaps in terms of capabilities were.
Three Mandatory Features
Three features kept surfacing as non-negotiable because the system kept breaking without them.
Declarative Workflow
When a run produced a bad result, I wanted the first question to be "what do I change about the process?" This meant the workflow had to be something that I could read and reason about at a high level. Not a quick-and-dirty script, not a black box inside someone else's tool. Treating the workflow as a diffable artifact meant I was able to experiment with it the same way I do with code: make a change, run it, compare results.
A nice benefit for the future is that the workflow as its own artifact becomes something that I can collaborate on with others. It can be shared, reviewed, and discussed as an asset of the team, not just my personal productivity tool.
Observable Operations
Each step in the workflow needs to produce data about what happened. For steps that prompt the agent that means the conversation and generated code. For shell commands or API calls, the inputs and outputs. Without this, debugging isn't possible. With this data, though, my tool was able to iterate autonomously. It could ask Claude to implement a feature, run tests and lints, and feed their output back into Claude to improve its implementation.
It also came in handy when the tool inevitably crashed. With full logs, it was easy to ask Claude to fix the bug. And then run the fixed version on the same task again, picking the work up from where it crashed. No wasted efforts, no tokens wasted.
Evidence-based Iteration
With observability data from individual runs, I was able to start asking bigger questions. How much does it cost to implement a typical task? How often does the agent get it right on the first attempt? How many review iterations are required before a pull request is ready to merge? There metrics turn gut feelings into empirical data.
This gave me confidence to iterate quickly. I was able to remove human gates from the workflow, because I had hard evidence across multiple runs that the quality did not drop. Without this kind of evidence, every change to the workflow is a leap of faith. With it, I was able to say "this version of the process is measurably better than the last one". This is what gave me trust.
Portability
Together, these three features create a feedback loop: define a workflow, run it, observe what happened, measure the outcome, and iterate. Each execution builds a little more confidence.
They also provide something else: independence. My workflow is no longer tied to a specific model or provider. Today Claude writes the code, tomorrow it might be Codex. I can swap them and compare the results. When a vendor changes their pricing, I can do the same without changing my process. The model is just a replaceable component inside it.
Conclusion
I started this experiment to test my own ideas about trust. What I found was that trust comes from owning a process you can observe and measure.
I believe owning the process might be the answer to the trust question I've been exploring. Not better models, not more review, but a workflow you own, can inspect, and can empirically improve.
If you're thinking about this too, or already building toward it, I'd love to hear from you. Send me an email to [email protected] or find me on Bluesky or Mastodon. 👋